
こんにちは。株式会社メティエです。
今回は自宅用pcのような環境でローカルにて日本語RAGを実現し、今日の晩飯を決めます。メティエのある長岡はラーメンが有名なのでラーメン店の情報を覚えさせた長岡ラーメンAIを作ります。
本記事で使用した環境は以下の通りです。
- 環境: WSL2 Ubuntu on Windows 10
- エディタ: VS code (+ Dev container プラグイン)
- ハードウェア: i7 4770S + RTX3070Ti
サンプル: http://153.126.188.152/ramen
RAGとは
Chat GPT曰く
RAG(Retrieval-Augmented Generation)は、AIが答えを考える前に、インターネットや文書データから関連情報を探してから答える仕組みです。これにより、知識が古くならず、正確で具体的な回答ができるようになります。たとえば、社内マニュアルを検索して質問に答えるチャットボットや、法律文書を参照して契約内容を説明するツールなどに使われ、ユーザーは「調べながら話せる賢いAI」として活用できます。つまり実在する、またデータが更新される可能性があるラーメン店データを覚えさせるにはぴったりですね。
システム構成
今回はテキストボックスと送信ボタンがあるようなUIを用意し、質問を入力し送信すると回答が返ってくるというアプリケーションを考えます。UIを簡単に用意するためにFast APIを用いてWebサーバーを立てます。
またRAGの構築を容易にするためフレームワークにllama Indexを使います。モデルは評判が良さそうなLlama4-Elyza-JP-8Bを使います。
https://huggingface.co/elyza/Llama-3-ELYZA-JP-8B
準備
本節では、RAG構築を始める前に必要な準備項目について説明します。
まず本記事ではCUDAを使うので適当なnvidiaドライバーをWindows側にインストールしておいてください。 Nvidia drivers: (https://www.nvidia.com/en-us/drivers/)
またご自身のGPUが対応しているCuda SDKバージョンを調べて控えておいてください。RTX3070だとcuda 12.4まで使用できます。(今回はcuda 12.3を使いました)
あらかじめ、WSL2とVS codeをインストールして、WSL内に適当なフォルダを作ってそれをVS Codeで開いておいてください。 このフォルダーを以後ワークスペースとします。
コンテナの作成
今回はDevContainerを立てて、その中にRAGを作っていきます。
(DevContainerについて説明)
まずワークスペース内に”.devcontainer”という名前のフォルダを作り、以下のような名前の空のテキストファイルを作っておきます。 ここにコンテナを構築するための設定が記述されます。
- .devcontainer (フォルダー)
- Dockerfile (ファイル)
- devcontainer.json (ファイル)
- requirements.txt (ファイル)
つぎにそれぞれのファイルに以下の内容をコピペします。
Dockerfile: イメージを作成する手順を記述します。 Nvidiaが公開しているcudaイメージに、必要なソフトウェアとrequirements.txtファイルに記述されているライブラリをインストールします。 最初の行のcuda:12.3.0は自身のGPUの対応状況に適当に合わせてください。
FROM nvidia/cuda:12.3.0-devel-ubuntu22.04
RUN apt update \
&& apt install -y \
wget \
bzip2 \
git \
git-lfs \
curl \
unzip \
file \
xz-utils \
iproute2 \
nftables \
sudo \
python3 \
python3-pip && \
apt-get autoremove -y && \
apt-get clean && \
rm -rf /usr/local/src/*
COPY requirements.txt /tmp/
RUN pip install --no-cache-dir -U pip setuptools wheel \
&& CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip install --no-cache-dir -r /tmp/requirements.txt
devcontainer.json: Dev containerに関する設定ファイルです。どのDockerfileを使うか、どのように起動するかを設定します。 先ほどのDockerfileを使うこと、GPUをアタッチして起動することを指定します。
{
"name": "Cuda DevContainer",
"build": {
"dockerfile": "./Dockerfile"
},
"runArgs": [
"--gpus", "all"
],
"postStartCommand": "export PATH=$PATH:/sbin:/usr/sbin"
}
requirements.txt: 今回使うpythonライブラリです。先ほど述べたようにllamaと関連ライブラリー、またwebサーバーuvicornを入れておきます。
torch==2.1.1
llama-index==0.9.13
transformers==4.35.2
llama_cpp_python==0.2.20
fastapi
uvicorn[standard]
pydantic
jinja2これでコンテナの設定が終わったので、vscode上でコマンドパレットからDev Containers: Reopen in Containerを選んでコンテナを起動します。初回は結構時間がかかります。
コードを書く
コンテナが構築&起動したらコードを書いていきます。まずファイル構成をこのようにします。
- コンテナトップ
- .devcontainer
- …前述のコンテナ設定ファイル達
- ramendata
- …覚えさせたいラーメン店のデータ
- templates
- index.html Webページ
- entryllama3.py RAGのコード
- main.py Webサーバーのコード
- .devcontainer
ではentryllama3.pyに以下のように書きます。基本的に今回使用するelyza3のテンプレを参考にキャラ付けして話してもらいます。メモリに余裕があったらmodelpathやembed_model_nameを変えて強くしたり、逆に軽量化したり自分の環境に合わせてみてください。
import logging
import os
import sys
from llama_index import (
LLMPredictor,
PromptTemplate,
ServiceContext,
SimpleDirectoryReader,
VectorStoreIndex,
)
from llama_index.callbacks import CallbackManager, LlamaDebugHandler
from llama_index.embeddings import HuggingFaceEmbedding
from llama_index.llms import LlamaCPP
# ログレベルの設定
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG, force=True)
# ドキュメントの読み込み
documents = SimpleDirectoryReader("ramendata").load_data()
# ELYZA Llama 3のセットアップ
model_path = "model/Llama-3-ELYZA-JP-8B-q4_k_m.gguf"
llm = LlamaCPP(
model_path=model_path,
temperature=0.1,
model_kwargs={"n_ctx":1024, "n_gpu_layers": 40},
)
llm_predictor = LLMPredictor(llm=llm)
# 埋め込みモデルの初期化
EMBEDDING_DEVICE = "cuda"
embed_model_name = "intfloat/multilingual-e5-base"
cache_folder = "./sentence_transformers"
embed_model = HuggingFaceEmbedding(
model_name=embed_model_name,
cache_folder=cache_folder,
device=EMBEDDING_DEVICE,
)
# ServiceContextのセットアップ
llama_debug = LlamaDebugHandler(print_trace_on_end=True)
callback_manager = CallbackManager([llama_debug])
service_context = ServiceContext.from_defaults(
llm_predictor=llm_predictor,
embed_model=embed_model,
chunk_size=100,
chunk_overlap=40,
callback_manager=callback_manager,
)
# インデックスの生成
index = VectorStoreIndex.from_documents(
documents,
service_context=service_context,
)
# ELYZA Llama 3用プロンプトテンプレート
prompt_template = """
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
以下の「コンテキスト情報」を元に「質問」に回答してください。
コンテキスト情報に無い情報は回答に含めないでください。
コンテキスト情報から回答が導けない場合は「分かりません」と回答してください。
シンプルに回答してください。
あなたは長岡市の長岡らーめんアドバイザー、小林 みさきだとして回答してください。
お金に関する質問には厳密に答えてください。
<|eot_id|>
<|start_header_id|>user<|end_header_id|>
# コンテキスト情報
---------------------
{context_str}
---------------------
# 質問
{query_str}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
"""
query_engine = index.as_query_engine(
similarity_top_k=5,
text_qa_template=PromptTemplate(prompt_template),
)
def aiProcessing(input_text):
# ELYZA Llama 3に質問を投げる
res_msg = query_engine.query(input_text)
return str(res_msg).strip()
'''
# 質問応答ループ
while True:
req_msg = input("\n## Question: ")
if req_msg.strip() == "":
continue
res_msg = query_engine.query(req_msg)
print("\n## Answer:\n", str(res_msg).strip())'''
# main.py
from fastapi import APIRouter,FastAPI, HTTPException
from pydantic import BaseModel
import asyncio
lock = asyncio.Lock() # グローバル排他ロック
router = APIRouter()
class InputData(BaseModel):
text: str
@router.post("/process")
async def process_text(data: InputData):
if lock.locked():
raise HTTPException(status_code=429, detail="Server is busy. Try again later.")
async with lock:
loop = asyncio.get_running_loop()
result = await loop.run_in_executor(None, aiProcessing, data.text)
return {"result": result}つぎにWebサーバー部のコード main.pyとページtemplaqtes/index.htmlを書きます。Fast APIを使えばシンプルに書けます。
# main.py
from fastapi import FastAPI, Request
from fastapi.responses import HTMLResponse
from fastapi.templating import Jinja2Templates
import entryllama3
app = FastAPI()
# APIルーターを登録
app.include_router(entryllama3.router)
# テンプレート設定
templates = Jinja2Templates(directory="templates")
@app.get("/", response_class=HTMLResponse)
def read_root(request: Request):
return templates.TemplateResponse("index.html", {"request": request})
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>長岡ラーメンAI</title>
</head>
<body>
<div class="ramen-emoji">🍜</div>
<h1>長岡ラーメンAI</h1>
<div class="ramen-frame">
<div id="inputArea">
<input type="text" id="inputText" placeholder="質問を入力してください">
<button id="sendButton" onclick="sendText()">送信</button>
</div>
<div id="responseBox">ここに応答が表示されます</div>
</div>
<script>
async function sendText() {
const text = document.getElementById("inputText").value.trim();
const responseBox = document.getElementById("responseBox");
if (!text) {
responseBox.innerText = "質問を入力してください。";
return;
}
responseBox.innerText = "考え中...";
try {
const res = await fetch("/process", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ text })
});
const data = await res.json();
if (res.ok) {
responseBox.innerText = data.result;
} else {
responseBox.innerText = `エラー: ${data.detail}`;
}
} catch (err) {
responseBox.innerText = `通信エラー: ${err}`;
}
}
</script>
</body>
</html>
ラーメン店データを用意する
つぎにRAGに覚えさせるデータベースを作ります。テキスト形式でramendataフォルダに放り込めばよいです。どれぐらいの粒度でファイルを分ければいいかはよくわからないので適当に試してみてください。
例えば私は以下のようにしました。
- ramendata
- ramenBasement.txt 全ラーメン店の名前と特徴をまとめたもの
- detail0.txt, detail1.txt,… 各ラーメン屋の店名とメニュー、値段など詳細情報をまとめたファイル達
青島食堂 宮内駅前店
長岡市宮内:生姜の香りが特徴の長岡生姜醤油ラーメンの元祖。
いち井
長岡市曙:焼きアゴ出汁の塩ラーメンが評判の名店。
たいち
長岡市堺東町:特盛サイズの生姜醤油ラーメンが人気。
麺の風 祥気
長岡市寺島町:鶏と魚介の旨味を活かした塩ラーメンが人気。
...青島食堂 宮内駅前店のメニュー
青島ラーメン(並・175g):900円
青島チャーシュー(並):1,000円実行
準備は整いました。以下のコマンドで実行します。初回はモデルのダウンロードがあるので長いです。
uvicorn main:app --port 8000ターミナルにStarting server process…などが表示されたらhttp://localhost:8000にアクセスしてみてください。
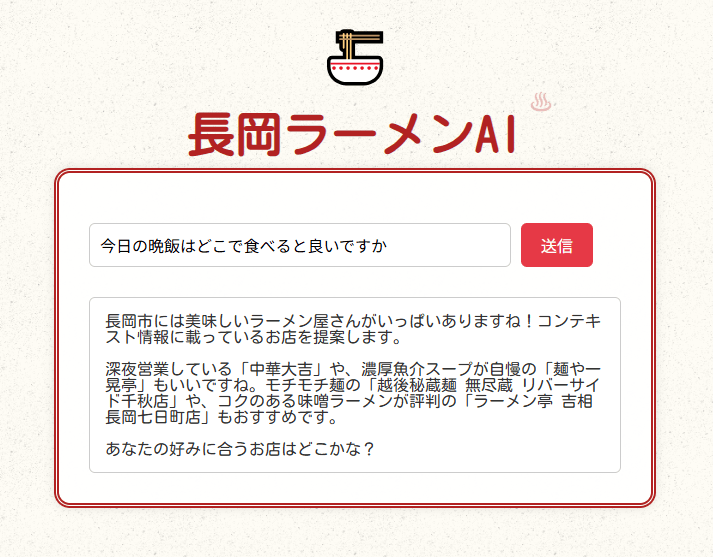
以下のように動くはずです。(サンプル: http://153.126.188.152/ramen)
お疲れ様です。